Reaction Details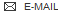 Report a problem with these data
Report a problem with these data
Report a problem with these dataTarget
Chromatin remodeling regulator CECR2
Ligand
BDBM310898
Substrate
n/a
Meas. Tech.
ChEMBL_1810766 (CHEMBL4310226)
IC50
240±n/a nM
Citation
 Wang, S; Tsui, V; Crawford, TD; Audia, JE; Burdick, DJ; Beresini, MH; C�t�, A; Cummings, R; Duplessis, M; Flynn, EM; Hewitt, MC; Huang, HR; Jayaram, H; Jiang, Y; Joshi, S; Murray, J; Nasveschuk, CG; Pardo, E; Poy, F; Romero, FA; Tang, Y; Taylor, AM; Wang, J; Xu, Z; Zawadzke, LE; Zhu, X; Albrecht, BK; Magnuson, SR; Bellon, S; Cochran, AG GNE-371, a Potent and Selective Chemical Probe for the Second Bromodomains of Human Transcription-Initiation-Factor TFIID Subunit 1 and Transcription-Initiation-Factor TFIID Subunit 1-like. J Med Chem 61:9301-9315 (2018) [PubMed] Article
Wang, S; Tsui, V; Crawford, TD; Audia, JE; Burdick, DJ; Beresini, MH; C�t�, A; Cummings, R; Duplessis, M; Flynn, EM; Hewitt, MC; Huang, HR; Jayaram, H; Jiang, Y; Joshi, S; Murray, J; Nasveschuk, CG; Pardo, E; Poy, F; Romero, FA; Tang, Y; Taylor, AM; Wang, J; Xu, Z; Zawadzke, LE; Zhu, X; Albrecht, BK; Magnuson, SR; Bellon, S; Cochran, AG GNE-371, a Potent and Selective Chemical Probe for the Second Bromodomains of Human Transcription-Initiation-Factor TFIID Subunit 1 and Transcription-Initiation-Factor TFIID Subunit 1-like. J Med Chem 61:9301-9315 (2018) [PubMed] Article More Info.:
Target
Name:
Chromatin remodeling regulator CECR2
Synonyms:
CECR2 | CECR2_HUMAN | Cat eye syndrome critical region protein 2 | KIAA1740
Type:
PROTEIN
Mol. Mass.:
164223.89
Organism:
Homo sapiens (Human)
Description:
ChEMBL_107999
Residue:
1484
Sequence:
MCPEEGGAAGLGELRSWWEVPAIAHFCSLFRTAFRLPDFEIEELEAALHRDDVEFISDLIACLLQGCYQRRDITPQTFHSYLEDIINYRWELEEGKPNPLREASFQDLPLRTRVEILHRLCDYRLDADDVFDLLKGLDADSLRVEPLGEDNSGALYWYFYGTRMYKEDPVQGKSNGELSLSRESEGQKNVSSIPGKTGKRRGRPPKRKKLQEEILLSEKQEENSLASEPQTRHGSQGPGQGTWWLLCQTEEEWRQVTESFRERTSLRERQLYKLLSEDFLPEICNMIAQKGKRPQRTKAELHPRWMSDHLSIKPVKQEETPVLTRIEKQKRKEEEEERQILLAVQKKEQEQMLKEERKRELEEKVKAVEGMCSVRVVWRGACLSTSRPVDRAKRRKLREERAWLLAQGKELPPELSHLDPNSPMREEKKTKDLFELDDDFTAMYKVLDVVKAHKDSWPFLEPVDESYAPNYYQIIKAPMDISSMEKKLNGGLYCTKEEFVNDMKTMFRNCRKYNGESSEYTKMSDNLERCFHRAMMKHFPGEDGDTDEEFWIREDEKREKRRSRAGRSGGSHVWTRSRDPEGSSRKQQPMENGGKSLPPTRRAPSSGDDQSSSSTQPPREVGTSNGRGFSHPLHCGGTPSQAPFLNQMRPAVPGTFGPLRGSDPATLYGSSGVPEPHPGEPVQQRQPFTMQPPVGINSLRGPRLGTPEEKQMCGGLTHLSNMGPHPGSLQLGQISGPSQDGSMYAPAQFQPGFIPPRHGGAPARPPDFPESSEIPPSHMYRSYKYLNRVHSAVWNGNHGATNQGPLGPDEKPHLGPGPSHQPRTLGHVMDSRVMRPPVPPNQWTEQSGFLPHGVPSSGYMRPPCKSAGHRLQPPPVPAPSSLFGAPAQALRGVQGGDSMMDSPEMIAMQQLSSRVCPPGVPYHPHQPAHPRLPGPFPQVAHPMSVTVSAPKPALGNPGRAPENSEAQEPENDQAEPLPGLEEKPPGVGTSEGVYLTQLPHPTPPLQTDCTRQSSPQERETVGPELKSSSSESADNCKAMKGKNPWPSDSSYPGPAAQGCVRDLSTVADRGALSENGVIGEASPCGSEGKGLGSSGSEKLLCPRGRTLQETMPCTGQNAATPPSTDPGLTGGTVSQFPPLYMPGLEYPNSAAHYHISPGLQGVGPVMGGKSPASHPQHFPPRGFQSNHPHSGGFPRYRPPQGMRYSYHPPPQPSYHHYQRTPYYACPQSFSDWQRPLHPQGSPSGPPASQPPPPRSLFSDKNAMASLQGCETLNAALTSPTRMDAVAAKVPNDGQNPGPEEEKLDESMERPESPKEFLDLDNHNAATKRQSSLSASEYLYGTPPPLSSGMGFGSSAFPPHSVMLQTGPPYTPQRPASHFQPRAYSSPVAALPPHHPGATQPNGLSQEGPIYRCQEEGLGHFQAVMMEQIGTRSGIRGPFQEMYRPSGMQMHPVQSQASFPKTPTAATSQEEVPPHKPPTLPLDQS
Inhibitor
Name:
BDBM310898
Synonyms:
N,N-dimethyl-3-(6-methyl-7-oxo-1H-pyrrolo[2,3-c]pyridin-4-yl)benzamide | US10150767, Example 22
Type:
Small organic molecule
Emp. Form.:
C17H17N3O2
Mol. Mass.:
295.3358
SMILES:
CN(C)C(=O)c1cccc(c1)-c1cn(C)c(=O)c2[nH]ccc12
Structure: